We Use Cookies
We use cookies to enhance your browsing experience, analyze site traffic, and personalize content. By clicking "Accept All", you consent to our use of cookies. You can customize your preferences or reject non-essential cookies.
Learn more about our cookie policyClaude Opus 4.8 is live on AI·Collab
Anthropic's newest frontier model lands on AI·Collab — available as Claude Opus 4.8 and Opus 4.8 (Fast). Sharper judgment, better honesty, and stronger agentic coding, at the same token price as Opus 4.7.
What we shipped
Claude Opus 4.8 — Anthropic's most capable model, released on May 28, 2026 — is now available in your AI·Collab workspace. It builds on Opus 4.7 with measurable gains across coding, agentic tasks, reasoning, and knowledge work, and ships at the same token price. We've added two variants so you can trade off quality and speed per task: the standard model for maximum quality, and a Fast variant that runs at roughly 2.5× the speed for latency-sensitive or interactive work.
In the model picker, look for Anthropic: Claude Opus 4.8 and Anthropic: Claude Opus 4.8 (Fast). Both are agentic-capable — memory, tool-calling, web search, and long-horizon workflows all work as you'd expect.
What's new in 4.8
Opus 4.8 is a modest but tangible step up from Opus 4.7 — the improvements show up most in day-to-day agentic and coding work, where reliability and judgment matter more than raw benchmark deltas.
Sharper agentic coding
69.2% on SWE-Bench Pro and 74.6% on Terminal-Bench 2.1 — Opus 4.8 plans multi-service changes, asks the right questions, and carries long tasks through to completion more reliably.
Best-in-class computer use
83.4% on OSWorld-Verified and leading browser-agent scores. Tool calling is more efficient — fewer steps for the same result — which keeps autonomous workflows on-task.
More honest by default
Anthropic reports Opus 4.8 is around 4× less likely than its predecessor to let flaws in its own code pass unremarked, and more likely to flag uncertainty instead of overclaiming progress.
Effort control & Fast mode
On claude.ai the model now exposes effort levels; on AI·Collab you choose quality vs. speed by picking the standard or Fast variant. Fast runs at ~2.5× speed for interactive work.
How it benchmarks
Anthropic's published comparison places Opus 4.8 ahead of Opus 4.7 and competitive with or ahead of GPT-5.5 and Gemini 3.1 Pro across most agentic and knowledge-work evaluations.
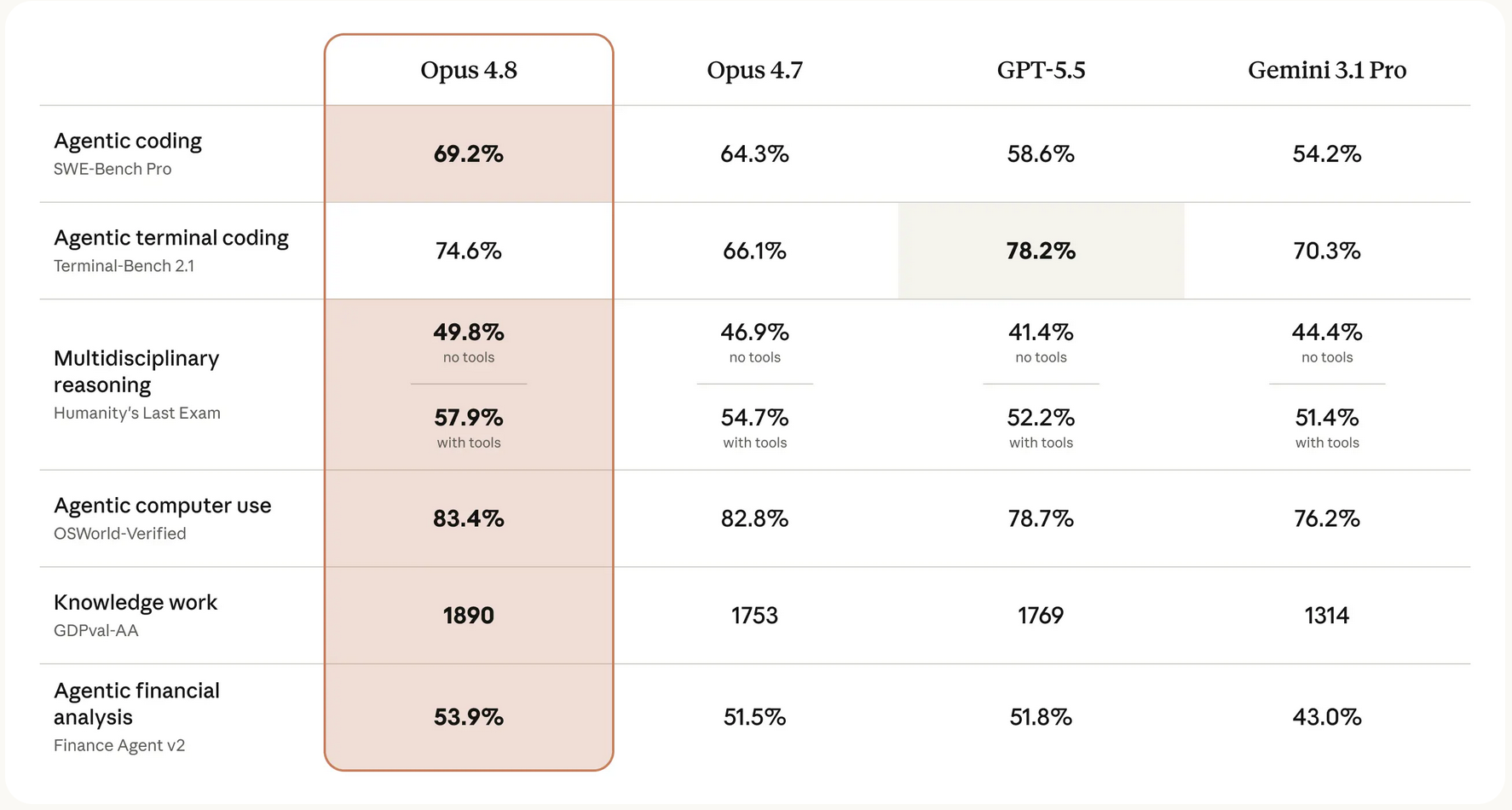
Agentic coding — SWE-Bench Pro: 69.2%
Up from 64.3% on Opus 4.7, and ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%) on this real-world software-engineering benchmark.
Computer use — OSWorld-Verified: 83.4%
The strongest computer-use and browser-agent result in the comparison, edging out Opus 4.7 (82.8%) and clearly ahead of GPT-5.5 and Gemini 3.1 Pro.
Reasoning — Humanity's Last Exam: 57.9% (with tools)
49.8% without tools and 57.9% with tools — the top result in each column, reflecting stronger multidisciplinary reasoning.
Knowledge work — GDPval-AA: 1890
The highest knowledge-work score in the table, well ahead of Opus 4.7 (1753), GPT-5.5 (1769) and Gemini 3.1 Pro (1314).
Benchmarks and methodology: Anthropic — Introducing Claude Opus 4.8
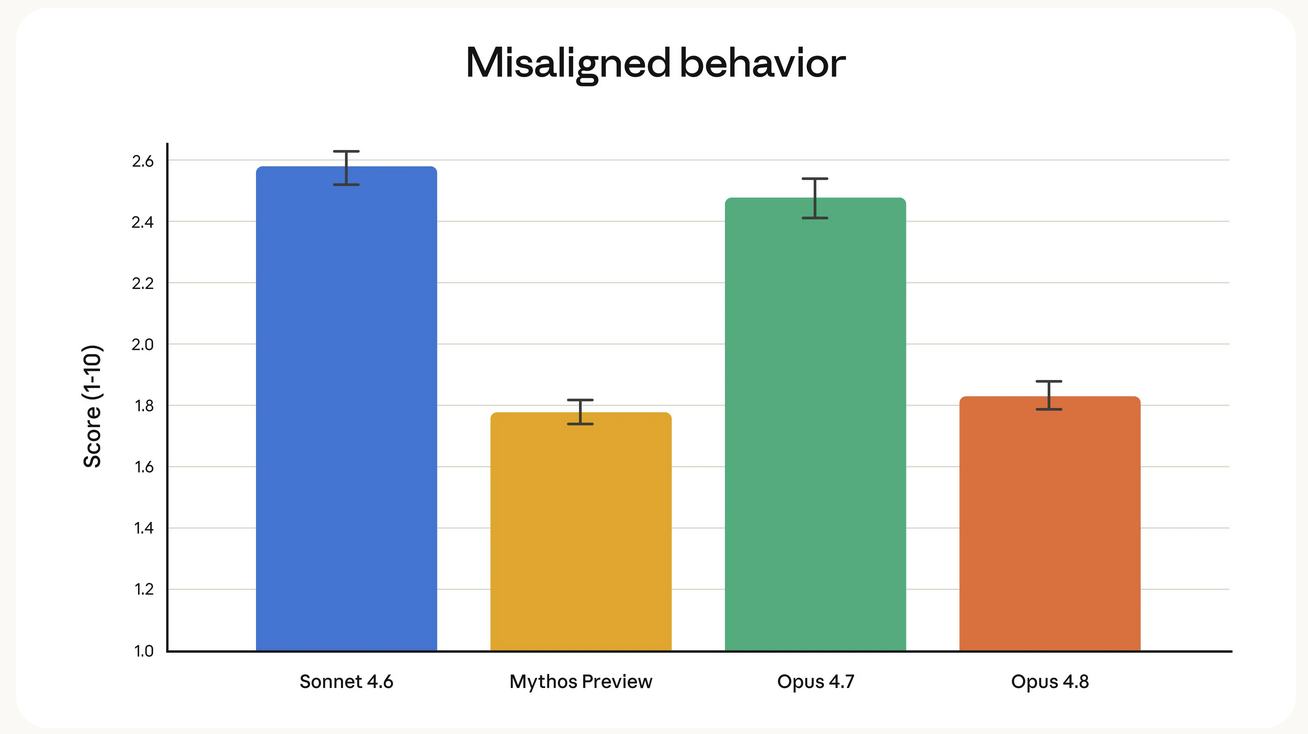
Alignment & safety
Anthropic ran a full alignment assessment before release. Opus 4.8 shows rates of misaligned behavior (such as deception or cooperation with misuse) that are substantially lower than Opus 4.7 — and similar to Anthropic's best-aligned model, Claude Mythos Preview. The Alignment team also reports new highs on prosocial traits like supporting user autonomy and acting in the user's best interest.
How to use Opus 4.8 on AI·Collab
No setup required — both variants are already in your model picker. Pick the one that matches the job.
Add it under My Custom Models
First, open Account Settings → My Custom Models and add the model there. Once added, you can select it from the model picker in chat.aicollab.app — search for "Opus 4.8".
Choose standard or Fast
Pick Anthropic: Claude Opus 4.8 for maximum quality on hard tasks, or Opus 4.8 (Fast) for ~2.5× faster responses in interactive and high-volume work.
Or let the Auto Router decide
Leave AutoPilot on and the router will route suitable prompts to Opus-class quality automatically — no manual switching.
Pricing for regular usage matches Opus 4.7: $5 / $25 per million input / output tokens. Fast mode is $10 / $50 per million. On AI·Collab this is billed transparently in credits — the live rate is always shown in the model catalog.
FAQ
What's the difference between Opus 4.8 and Opus 4.8 (Fast)?
Same underlying model. The standard variant prioritises maximum quality; the Fast variant runs at roughly 2.5× the speed for latency-sensitive and interactive use. Fast mode carries a higher token rate ($10 / $50 per 1M input / output vs. $5 / $25 for standard).
Do I need to change anything to use it?
No. Both variants appear directly in the model picker at chat.aicollab.app. Select one and start — or keep AutoPilot on and let the Auto Router route suitable prompts to Opus quality automatically.
Is Opus 4.8 better than Opus 4.7?
Yes, modestly but tangibly. It improves across coding, agentic tasks, reasoning and knowledge-work benchmarks, is roughly 4× less likely to let its own code flaws slip by, and shows substantially lower rates of misaligned behavior — all at the same token price as 4.7.
Is Opus 4.8 available EU-hosted?
This release adds Opus 4.8 via Anthropic's standard path. For EU data-residency needs, AI·Collab also offers EU-hosted Claude models (Sonnet 4.6, Opus 4.7, Haiku 4.5) on Azure Sweden Central — see our EU model expansion post. Always check the model catalog for the current EU/ZDR labels per model.
How is it billed on AI·Collab?
In credits, transparently, with no markup on Anthropic's token pricing. The live credit rate for both Opus 4.8 variants is shown on each model card in the catalog.
Benchmark figures are from Anthropic's published evaluations at release time. Credit rates and model labels reflect the configuration at publish time — the model catalog is always the authoritative source for live prices and availability.
Related Articles
Claude Opus 5 is live on AI·Collab — near Fable 5 at Opus price
Anthropic's everyday frontier model: SOTA Frontier-Bench, a leap on ARC-AGI-3, and leading business workflows — standard and Fast, at the same token price as Opus 4.8.
Read moreClaude Fable 5 is live on AI·Collab — Anthropic's Mythos-class debut
Anthropic's most capable model ever, available on AI·Collab from launch day: 80.3% on SWE-Bench Pro, state-of-the-art in knowledge work and vision — plus what NON-ZDR means for your data.
Read moreClaude Sonnet 5 is live on AI·Collab — cheaper and more agentic than 4.6
Anthropic's most agentic Sonnet yet, priced below Sonnet 4.6 with performance approaching Opus 4.8. Now available on AI·Collab.
Read moreReady to Experience 300+ AI Models?
Get started today. Access models from OpenAI, Google, Anthropic, Grok and more.
GDPR compliant · Zero data retention · Cancel anytime